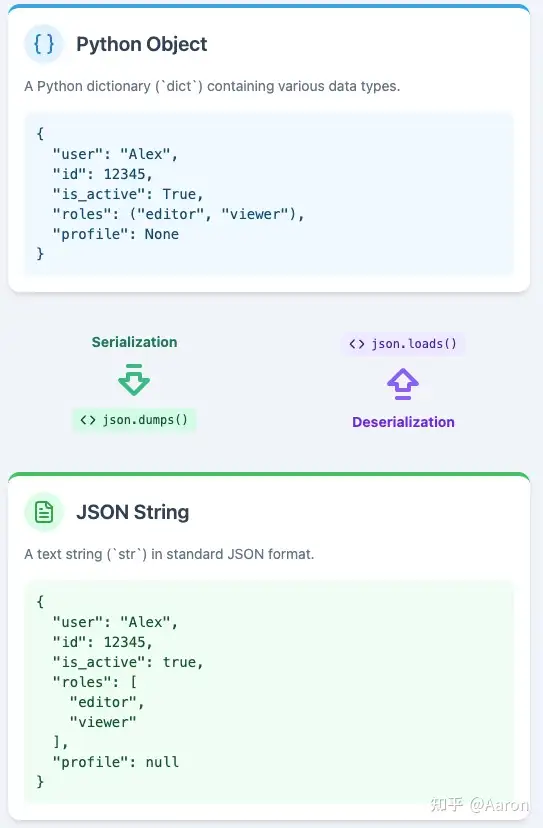
前情提要
2020年还是初学编程的时候,我偶然翻到过一门讲函数式编程的课,课程链接早已找不到,但是其中一节课作业是实现一个简洁的 JSON parser。我经常在写 Web 软件中用到 JSON,但是从没想过怎么实现它。仔细琢磨发现它的语法是递归的,一时半会没有什么思路,当时就埋下了好奇的种子。
在 2021 年的时候我学习了编译器,并且实现了一个类似于 C 语言的编译器。2022年的时候,我也写过一篇文章介绍了解析 JSON 语法的算法,附带一个简略的实现。
到了今年,我想是时候尝试实现一个相对完整的 JSON 库,包括序列化和反序列化,还有所有的配置参数,于是我就选定了 Python 的 json 库。写完之后我发现其实这个库并不会用到特别复杂抽象的编译器知识,难度上更多是集中在软件工程上,再就是大量关于字符串编码的细节。
希望本文可以带感兴趣的读者体验下:实现一个相对完备的 JSON 库的过程中,会有哪些乐趣和难点。源代码链接在此。配合文章和源码,会更容易掌握。当然你也可以直接略过源码尝试自己动手实现。
Python 的 json 库包括两个版本,纯 Python 实现和 C 扩展实现,Python 实现的源码路径在 /Lib/json,C 扩展的源码路径在 /Modules/_json.c。作者的目的是希望速度快,但是又能在纯 Python 的环境运行(比如 Pypy)。因为我现在专注于 Python 方面的工作,所以我只用纯 Python 实现了我提到的功能。开始写时,Github 上最新的源码版本是 Python 3.15,所以我就选择了这个版本(但这里也埋下一个问题,导致后续实现相关功能时遇到了障碍,毕竟第一次尝试复现开源库,经验不足)。
前后大约耗时三周,我通过了几乎所有的官方测试用例。没有通过的包括
- C 扩展特定的测试用例(因为我没有用 C实现)
- 命令行工具相关的测试用例(前文提到我下载了3.15 版本源码,尤其是要用到里面的测试,但是刚开始写这个项目时,最新可下载的解释器是 3.14, 所以测试中用到的一些 API 在 3.14 版本的解释器缺失,无法正常运行)
此外我没有实现解析 JSON 时打印详细的错误信息功能,这属于帮助功能,所以并未在官方测试用例中体现,我也就略过了。
其中程序量大概700行,测试800行。而程序量和测试量的比例竟然达到了 1:1 。
其实我只用了两三天就实现了基础的 loads 和 dumps 的功能,但是后续的配置参数中遇到了一些困难,而且里面涉及到 Unicode 和 Escape character 的部分尤其晦涩,耗费了我不少精力去查资料。
AI 与官方源码的使用
因为我的目的是深刻理解 json 库,所以没有用 AI 去生成程序,主要是查询了关于 JSON 中 Unicode 和 Escape character 的内容,放在以前这本质上就是“故纸堆里翻资料",属于我不感兴趣的体力活。
此外 关于 Unicode 里面的一些处理细节我也参考了官方的源码,比如拿到一个字节流要如何区分它的编码是 UTF-8/UTF-16/UTF32 中的哪一种,而且 UTF-16 和 UTF-32 还要区分大端法和小端法,这些对我太琐碎了,未来很难用得上;写反序列化功能时,词法分析的正则表达式是用 AI 生成的,因为我当时对正则表达式语法不太熟悉,后续在这个生成的正则表达式上改了改。
关于原作者:Bob Ippolito 的故事
研究一个软件时,我最感兴趣的就是背后作者的故事。作者叫Bob Ippolito。最早将 simplejson 作为一个第三方库来实现,后来 Python 官方将其纳入了标准库。
从博客来看,Bob 感兴趣的方向有 Haskell、Python、Web 软件、Erlang、Javascript。还做过一个仿照可汗学院的教小孩编程的网站。
从履历看,Bob 第一次实习是 1997 年,算是经历了当年最早的互联网浪潮的老手,截至目前已经经历了十家公司,跳槽非常高频,而且大部分都是作为 CTO。后来2012年创办的公司被收购,在 Facebook 也曾工作过几个月。现在兼职在一家加州的慈善机构教高中生编程。小公司、大公司、创业成功、尝试教学,这样的履历让我心向往之!
他的编程方向跨度很广,包括 Web 软件、游戏、RFID、iPod 软件、IOS 虚拟化(可以在浏览器运行 IOS 应用)。
综合来看是典型的 Hacker,兴趣广、钻研深,热爱编程,喜欢教学。
实现的思路
JSON 本质上其实是 Javascript 语言中描述数据结构的子集,从这个角度提纲挈领更容易理解。
官方库中所有的功能有两种分类方法,第一种就是分为序列化和反序列化,序列化就是把 Python 的数据结构转成 JSON 文本字符串,反序列化就是把 JSON 文本字符串转为 Python 的数据结构,两者的顺序是相反的;第二种就是分为核心功能和配置参数,核心功能就是最基础的序列化和反序列化,配置参数包括了比如实现 JSON 的超集、容错性、格式化等等。
如下是官方库的函数签名,里面的每个参数都是一个特殊的功能,指定库的一种特殊行为,比如 parse_constant 是实现了 JSON 的超集,针对官方文档实现了更多的浮点数类型,check_circular 是对数据结构进行了环的检测,防止程序卡死。
def loads(s, *, cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
pass
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
pass
在依赖关系上,序列化和反序列化是并行的,而配置参数依赖于核心功能。
所以我的计划是先大概通读一遍 JSON 的 RFC 还有官方库的文档,然后先尝试实现基础的序列化和反序列化,这个过程中所有的测试用例也都是我按照平时使用的直觉写的。
这里着重讲下反序列化的架构和算法。
这里最重要的就是理解 RFC 中的 grammer 部分,了解语法层面 JSON 由哪些符号构成;其次就是理解 JSON 的语法结构,分为基础类型(primitive types) 和复合类型(structured types)。而且复合类型是递归的,所以这里要涉及到大量的递归操作。
理解了之后,就可以大概将问题做如下的分解:
数据有三个阶段,JSON text、tokens(中间阶段,将字符串分解为具有意义的子单元)、Python object,其中分两个步骤,第一步是词法分析(Lexical Analysis),将 JSON text 转为 tokens,第二步是语法分析(Syntax Analysis),将 tokens 转为 Python 的 object。
这里我采用了典型的编译器的架构,将数据一步步转换为越来越接近目标的格式,后续可以看到官方库采用了高性能但是可读性略差的写法。面对比较简单的语法是可以这样的,但是现代的编译器比如 Go、Python 普遍都是分两步来解析的。
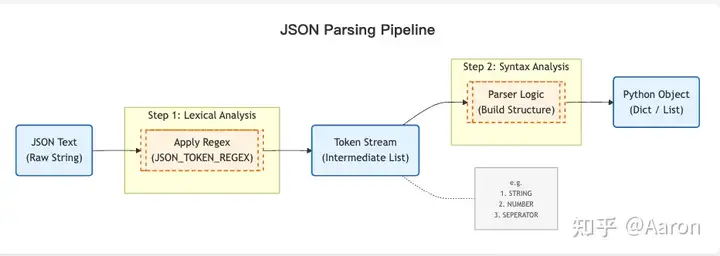
关于 tokens 解析,我们这里不讲编译器的知识,更多从一个朴素的直觉来理解,面对一个字符串
"3 5 2 8 6"
假设我们想要把字符串里面的数字进行排序,要怎么做?按照直觉来看,我们要将其转成一个可以排序、对比大小的数据结构,于是很自然的,我们将其 split 成一个 list,然后把里面每个元素转成数字类型,如下:
>>> b = map(lambda x: int(x), "3 5 2 8 6".split())
>>> list(b)
[3, 5, 2, 8, 6]
这里的思路是一样的,我们用正则表达式,可以直接将 JSON 文本转成一个个 token,每个 token 都是一个有意义的单元,包括 token 的类型和值,典型的例子如下:
"""
{
"name": "Project Alpha",
"version": 1.2,
"is_active": true,
"metadata": null,
"developers": [
{"id": 101, "role": "lead"},
{"id": 102, "role": "backend"}
],
"description": "A test string with an escaped quote \\" here."
}
"""
[
("SEPERATOR", "{"),
("STRING", '"name"'),
("SEPERATOR", ":"),
("STRING", '"Project Alpha"'),
("SEPERATOR", ","),
("STRING", '"version"'),
("SEPERATOR", ":"),
("NUMBER", "1.2"),
("SEPERATOR", ","),
("STRING", '"is_active"'),
("SEPERATOR", ":"),
("LITERAL", "true"),
("SEPERATOR", ","),
("STRING", '"metadata"'),
("SEPERATOR", ":"),
("LITERAL", "null"),
("SEPERATOR", ","),
("STRING", '"developers"'),
("SEPERATOR", ":"),
("SEPERATOR", "["),
("SEPERATOR", "{"),
("STRING", '"id"'),
("SEPERATOR", ":"),
("NUMBER", "101"),
("SEPERATOR", ","),
("STRING", '"role"'),
("SEPERATOR", ":"),
("STRING", '"lead"'),
("SEPERATOR", "}"),
("SEPERATOR", ","),
("SEPERATOR", "{"),
("STRING", '"id"'),
("SEPERATOR", ":"),
("NUMBER", "102"),
("SEPERATOR", ","),
("STRING", '"role"'),
("SEPERATOR", ":"),
("STRING", '"backend"'),
("SEPERATOR", "}"),
("SEPERATOR", "]"),
("SEPERATOR", ","),
("STRING", '"description"'),
("SEPERATOR", ":"),
("STRING", '"A test string with an escaped quote \\" here."'),
("SEPERATOR", "}"),
]
背后的正则表达式如下:
JSON_TOKEN_REGEX = re.compile(
r"""
# 1. 字符串 (最复杂,优先匹配)
(?P<STRING> " (?: \\. | [^"\\] )* " )
# 2. 数字
| (?P<NUMBER> (-? \d+ (?: \. \d+ )? (?: [eE] [+-]? \d+ )? | Infinity | -Infinity | NaN ) )
# 3. 字面量
| (?P<LITERAL> true | false | null )
# 4. 分隔符
| (?P<SEPERATOR> [{}[\],:] )
# 5. 空白 (需要被忽略)
| (?P<WHITESPACE> \s+ )
# 6. 错误/不匹配项 (用于捕获非法字符)
| (?P<MISMATCH> . )
""",
re.VERBOSE,
)
拿到 token 之后,我用了 Python 的 deque 来承载,因为接下来有大量的弹出第一个元素的操作,deque 是用链表写的,这个操作的时间复杂度为 O(1)。
接下来我们先从基础类型入手,如果是 null 的话,直接返回对应的 Python 内置类型 None 即可,true、false 返回 Python 的 True、False,number、String 以此类推。
到了复合类型会棘手一点,但是按照语法规则即可。用 Array 为例,我们拿到的 Array tokens 一定是如下的格式:
array = begin-array [ value *( value-separator value ) ] end-array
举个例子,也就是
[1, 2, 3]
那么就去掉开始符号,递归读取第一个元素,去掉分隔符,然后读取下一个元素,以此类推。
这里的架构主要是相互递归地解析。比如 Array 里面可能套 Array,object 里面套 object。
分别有四个函数,_parse_value(处理 JSON 中的 value,可以代表任何类型)、_parse_primitive_value(处理 JSON中的基本类型,null、String 等等)、_parse_object(处理 JSON object)、_parse_array(处理 JSON Array)。
这里的思路主要源于 JSON 语法本身,利用语法本身自然能得到这样的分类和相互递归的关系。
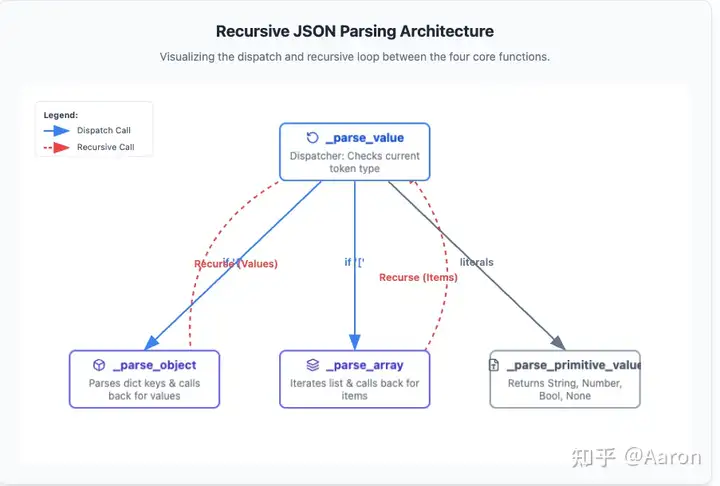
而序列化本质就是拼接字符串,仍然可以按照基础类型、复合类型的方式去拼接。
实现完之后就可以尝试通过官方的所有基础的测试用例了,实现基础的序列化和反序列化的工作量小到出乎我的预料,只用了两三天我就实现了。剩余的测试用例基本都是围绕配置参数展开的,比如 default、ensure_ascii、check_circular 这些参数,每个都有对应的测试用例。我基本就是按照测试用例,再去读相应的测试文档,然后一个个实现这些参数功能。
难点解析
这个程序最难的就是递归关系,递归程序不是线性的,所以天然反直觉。
但是我之前学习函数式编程写了大量的递归,现在面对递归已经很舒服了。不过 debug 的过程中它的数据流仍然很难阅读,而且后续性能测试时也带来了不小的麻烦。
真正出乎我意料的是序列化里面的配置参数,这里的工作量反而占了大头,有三个功能比较复杂,第一个就是检测环的算法,第二个就是格式化的功能,第三就是字符串中特殊符号的处理。
检测环:在 Python、Javascript 这样的语言中,数据结构是可能有环的,比如:
a = {"b": None}
b = {"a": a}
a['b'] = b
print(a)
# {'b': {'a': {...}}}
这样有环的数据结构,如果直接做序列化会程序卡死,因为在序列化的时候要遍历整个数据结构。所以需要用到一些图论的基础知识,来检测一个有向图是否有环。虽然图论听起来很抽象,但是在这里其实很具体,读者不必担心,用生活中的直觉来举例,如果一个人在森林中迷了路,要怎么办?很自然可以想到做标记,比如找一些特殊的石头、木棍,在自己走过的地方摆放标记。
对于图中环的检测也是一样,在遍历图的过程中,一旦遇到了遍历过的节点,就可以判定是环了,然后报错。所以我用了一个 set 来存放遍历过的节点,但是在通过官方的测试用例报错了。仔细一看,发现还有一种情况,就是共享引用:
a = True
b = {"b": a}
c = {"c": a}
这种情况下是没有环的,但是用以上的粗暴算法却会判定有环,所以我们需要更新一下算法:针对复合结构,记录 Array 和 object 类型的节点,但是一旦从这个节点退出时,就要从标记的 set 里面去除这个节点。
格式化:格式化看起来很简单,但是里面的用例情况特别多,最后我借鉴了 React 思想,抽象出一个状态值代表缩进层次(indent Level),我会在递归的过程中不断增加和减少缩进值,也就是修改状态值,然后在渲染的时候根据状态值直接显示缩进的层数。也就是将状态和渲染分离,这样将问题分解为独立的两部分,解决起来更容易下手。
和解析 JSON 的思路一样,这里需要从最简单的 case 入手,一步步累加到越来越复杂的 case。
字符串的处理 :这里主要面临两大挑战,一是转义字符(Escape character),我需要仔细了解转义字符有哪些类型,JSON 中的转义字符和 Python 中的转义字符不是一一对应的,需要做一次重映射,我需要很小心的理解所有类型,并且进行映射。
这里面的工作包括
- 处理引号 "
- 处理转义引号带来的反斜杠 \
- 处理 ASCII 码遗留下来的特殊控制字符 \n \t 等等
- 处理 Unicode 的转义,比如希腊字母 α 就是转成 \u03b1,表情符号 😀 转成 \U0001f600(最终转成\ud83d\ude00),这里的16进制数字就是 Unicode 的码点(code Point),类似于一个身份证 ID,这个 ID 再转成最底层的二进制字节编码
- 其中 Unicode 的码点又有一个 BMP 的概念,可以把BMP理解成一个集合,最初设计者没想到 Unicode 会涉及这么多字符,所以给码点规定为四位十六进制数(在 BMP 集合内),结果后来字符集越来越大,超出了 BMP 的范围,于是使用了一些算法,将一个超出范围的码点用两个四位十六进制数来表示,而 JSON 库的解析中需要实现以上的算法(当初看到这里我也有些头晕,这已经涉及编码很底层的细节了)
二是 Unicode,JSON是兼容 UTF-8、UTF-16、UTF-32的,所以需要在接收到字节流的时候判断选择哪种编码格式,我在这里选择了直接参考官方源码,因为太 tricky 了。
此外 JSON 库中有一个类似于 Javascript downleveling 的功能,当 Javascript 新版本发布后,很多环境还不支持,有一些软件就会将新功能的 Javascript 编译成旧的版本,这样那些旧环境也可以运行新的 Javascript。对于 JSON 库来说,就是 ensure_ascii 这个功能,它会把所有的 Unicode 字符串转成 ASCII 码,这样只支持 ASCII 码的环境也可以正常解析这些 JSON 格式的数据。这里需要了解 Unicode 中 BMP 的概念,还有转换规则,感谢 AI 节省了我很多查找相关资料的时间。
除此之外还有一点,就是功能之间不是完全正交的,比如 default 功能和检测环的算法就是互相影响的,我刚开始完全没有考虑到,直到碰到了官方的测试用例才明白。我的想法是,这种情况需要一个很熟悉这个库的人来把控,不能很贸然引入影响旧功能的新功能,这已经超出了纯粹的编程角度,更多是从产品经理和项目管理的角度去进行把控,如果有十个功能是相互影响的,他们产生的关系数量就是 n 的累加,也就是 55 种关系,这种关系的增加是爆炸性的,指数级别的。如果这一步做不好,整个软件的维护成本会爆炸式上升。
源码阅读和对比
当我通过了所有的测试用例之后,就自然开始阅读官方的源码,主要是官方库中 Python 的 JSON 实现。
初读源码,给我的感觉是程序很老练简洁,尤其是关于序列化的部分,非常整洁,层次感很强,比如配置参数里面有 parse_float、parse_int 这些高阶函数作为参数,而官方库中的 Array 和 object 也都使用这样的高阶函数实现的,然后传入,实现了一种整齐划一的感觉。
此外序列化这里,作者使用的方法是将整个字符串一次扫描,在扫描的过程中一边解析 token,一边构造映射的 Python 的数据结构。这样写和读都更难一些,因为把两步压缩到了一步,但是好处是性能更高。
此外也说说缺点,源码实现了 C 扩展和纯 Python 两个部分,外面套了一层 Python OOP 风格的薄薄的 API,但是里面的源码都是用函数和高阶函数实现的,用高阶函数当做参数传入,来模拟 OOP,这是典型的 C 风格的写法,所以里面的 Python 更像是 C 风格的 Python,读起来有些绕。
比如原作者实现了一个叫 make_scanner 的函数,为了让它在 C 和 Python 中保持统一,用了典型的 C 的写法,用一个 context 来传递类的方法和数据,而 Python 中其实直接把 make_scanner 作为类的方法即可:
def py_make_scanner(context):
parse_object = context.parse_object
parse_array = context.parse_array
parse_string = context.parse_string
match_number = NUMBER_RE.match
strict = context.strict
parse_float = context.parse_float
parse_int = context.parse_int
parse_constant = context.parse_constant
object_hook = context.object_hook
object_pairs_hook = context.object_pairs_hook
memo = context.memo
我本来没打算把自己写的源码放出来,但是发现官方库为了性能考量和兼容 C 扩展,其实牺牲了可读性,而我的程序可读性更强,同时也实现了完备的功能,所以就放出来以供读者借鉴。
性能测试与分析
学习 JSON 的过程中,我偶然看到了 Github 上有一个 JSON 性能测试的仓库,就用里面的数据,针对我的实现还有 json 库中 Python 实现和 C 扩展实现做了性能测试。这是我第一次接触实际中的计算密集型的程序,之前我在公司做 Web 后端软件时,接触到的所有性能瓶颈几乎都是 IO 层面的,唯一的例外可能就是数据库慢查询,需要用索引,或者是数据库操作一些产品经常锁全表,就改用了 Redis 来操作。
实测下来,官方库 Python 实现耗时大概是 C 实现的三倍,这点很出乎意料,我以为 C 和 Python实现可以相差十倍的性能,没想到并没有拉开数量级上的差距。
而我的程序中,序列化的耗时大概是官方库 Python 实现的 1.2 倍,这个可以理解,官方库毕竟有一些细微的优化,我更多是考虑程序的正确性;但是反序列化的耗时是官方 Python 实现的 50 倍!
| 实现版本 | 序列化 (dumps) 相对耗时 | 反序列化 (loads) 相对耗时 |
|---|---|---|
| 官方 C 扩展 | 1x (基准) | 1x (基准) |
| 官方 Python 实现 | ~2x | ~3x |
| 我的实现 | ~2.4x | ~150x |
刚开始我以为自己看错了,因为毕竟也是考虑了性能的,专门换用了高效的数据结构 deque 来装 tokens,接下来第一反应是可能因为用了两次扫描,尤其第一次扫描写的正则表达式太低效。但是测试之后发现第一次扫描解析 tokens 只占用了大概 1/15 的时间。
于是我用分析工具跑了一编,但是在构建数据结构这里需要大量的相互递归,它和普通的线性程序不同,比如一个服务器请求,调用的函数分别为 A、B、C,通过性能测试我们能知道耗时瓶颈在哪里,可是对于 JSON解析,需要用到相互递归,A、B、C 是互相调来调去的,导致里面的每个函数的耗时都差不多,和总耗时接近,根本没有有效信息。
于是我就去打了会篮球来放松神经系统,期间一直在琢磨。第二天打开程序看到了里面 debug 用的日志,一检查发现我打印的日志有将近一个 G,于是关闭所有日志之后,我的程序耗时大概占官方 Python 实现的 五倍,考虑到我做了两次扫描,又在内存中维护了一个很大的 deque,这个性能就算接近正常了。
最终的效率对比如下:
| 实现版本 | 序列化 (dumps) 相对耗时 | 反序列化 (loads) 相对耗时 |
|---|---|---|
| 官方 C 扩展 | 1x (基准) | 1x (基准) |
| 官方 Python 实现 | ~2x | ~3x |
| 我的实现 | ~2.4x (对比官方Py) | ~15x (对比官方Py) |
写完本文后,发给以一位朋友看,他提示我说可以考虑用生成器来装 tokens,这样性能可以有加速。于是我就尝试了一下重构,恰好我之前把 tokens 封装成了一个类,如下:
class Tokens:
def __init__(self):
self._tokens = deque()
def append(self, element):
self._tokens.append(element)
def peek(self):
return self._tokens[0]
def empty(self) -> bool:
return len(self._tokens) == 0
def next(self):
return self._tokens.popleft()
def to_list(self):
return list(self._tokens)
这里就展现了软件工程中抽象封装的威力:最开始的 tokens 只是一个 list,然后我在程序的各处实现了类似 next、peek 的 操作,写到后面我意识到这里的操作高度相关,所以把他们聚合实现了一个类,然后把底层的 list 改成了 deque。到了现在想要替换 deque 为迭代器实现就变得一样轻松``,因为这里做了封装,所以外部的 API 可以几乎保持不变,只要把内部的实现改变即可,配合上测试很容易就完成了重构。如下:
class Tokens:
def __init__(self, iter):
self._tokens = iter
self.next_token = None
def peek(self):
if self.next_token is None:
self.next_token = next(self._tokens)
return self.next_token
else:
return self.next_token
def empty(self) -> bool:
try:
self.next_token = next(self._tokens)
return False
except StopIteration:
return True
def next(self):
if self.next_token is None:
return next(self._tokens)
else:
token = self.next_token
self.next_token = None
return token
def to_list(self):
return list(self._tokens
不过遗憾的是重构完之后,性能相比之前没有什么变化,所以和我猜想的一致,确实是一次扫描和两次扫描带来的差距,lua 解释器本身也使用了一次扫描的技术来加速。
我学到了什么
首先是生产中做反序列化,应该使用一次扫描。但是高性能的代价往往是牺牲可读性(比如用 CPP 重写 Python 的程序),要做好权衡。
其次官方源码中大量使用了正则表达式。我之前总觉得正则表达式是奇技淫巧,可读性太差,但是在某些情况下,大量解析字符串,它可以代替很多手写的逻辑,很方便。就比如 JSON 格式中的数字,如果完全用 if else 逻辑来手写的话,就很啰嗦。而且 Python 的正则表达式引擎实现了一种方言,里面可以加缩进和注释,大幅度提升了可读性,所以接下来我也打算系统学一遍正则表达式。
然后就是不要太崇拜官方的源码,没有程序是完美的,官方的源码因为各种权衡,反而会有一些缺点,比如 json 库为了提供 Python 和 C 两套实现,导致 Python 程序完全是 C 风格的,读起来有些晦涩。
最后坦诚讲讲我的实现的缺点,我对于 JSON 中字符串编码细节不够了解,很多写法都是现学现卖,测试用例能够覆盖的情况终归是有限的,这就导致在处理字符串的 corner case 时,我的程序是不够健壮的。事实上虽然通过了官方几乎所有的测试,但在做性能测试时还是发现了一个转义字符处理的 bug。
就像 John Carmack 讲的,测试无法解决设计上的问题。这里本质上是我在领域知识上的薄弱之处。